Information ist das, was wir nicht wissen.Diese – scheinbar vielleicht überraschend klingende – Definition sagt, daß das, was wir schon wissen, für uns keine Information mehr ist. Sie macht Information weiterhin zu einem subjektiven Begriff. Wir werden also nicht danach fragen, wieviel Information objektiv etwa in einer Nachricht steckt, sondern wieviel darin für uns subjektiv neu ist. Das kann für verschiedene Menschen unterschiedlich viel sein, und hängt für ein und denselben Menschen davon ab, wie genau er die Nachricht schon vorher gekannt hat.
Zur quantitativen Definition von Information betrachten wir einen Versuch, der zwei mögliche Ausgänge hat und dessen Ausgang wir nicht vorhersagen können. Wir nehmen also an, daß beide Versuchsausgänge für uns gleichwahrscheinlich seien. Als Beispiel können wir uns das Werfen einer Münze vorstellen, bei dem wir nicht wissen, ob die Münze Vorder- oder Rückseite zeigen wird. Die Menge an Information, die uns ein solcher Versuch liefert, erklären wir zur Maßeinheit der Information:
Der Informationsgehalt eines Versuchs mit zwei gleichwahrscheinlichen Ausgängen beträgt 1 bit.
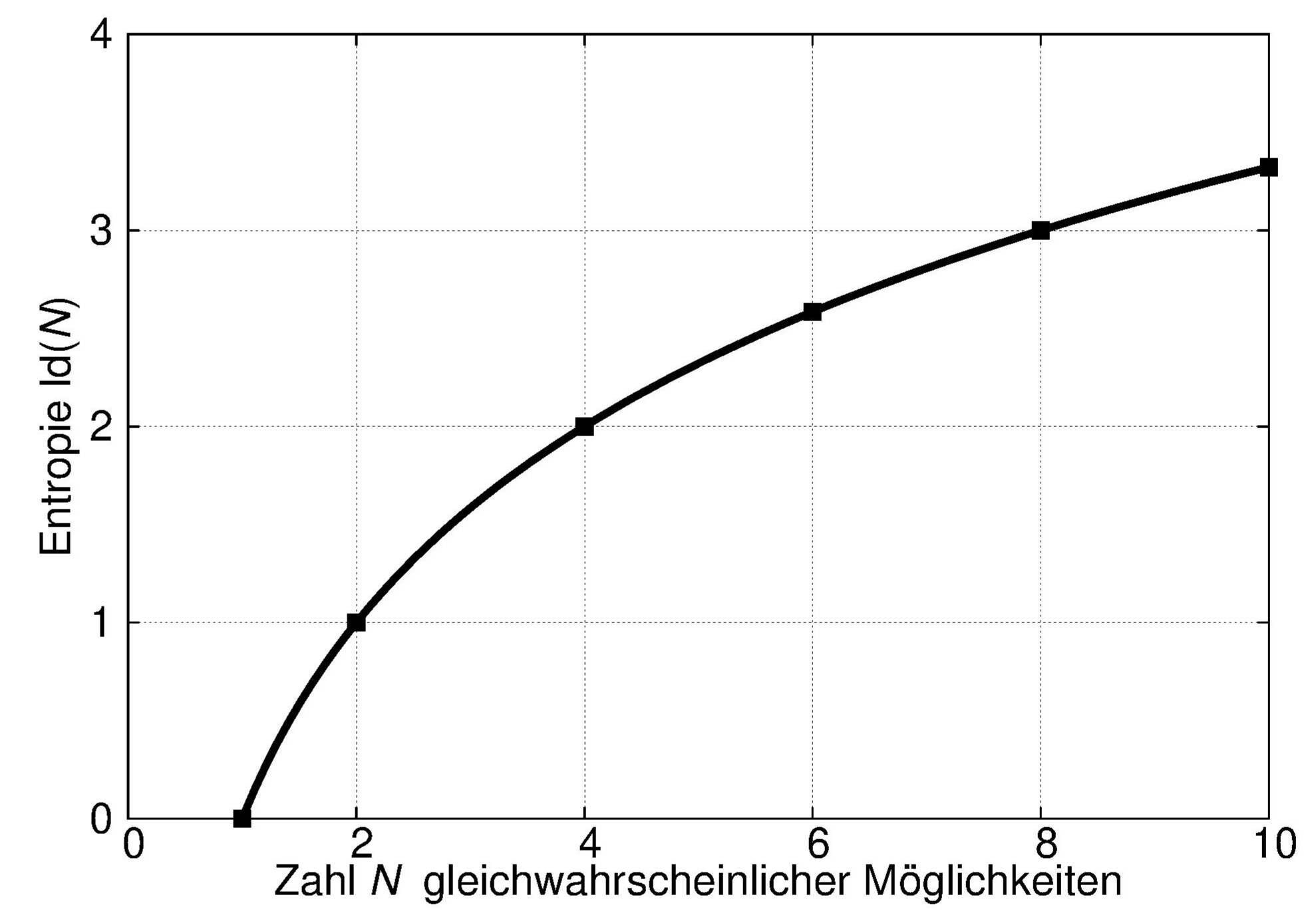
Der Anwendungsbereich dieser Definition läßt sich leicht erweitern. Nehmen wir an, ein Versuch habe N = 2n gleichwahrscheinliche Ausgänge. Wir können sie in zwei gleich große Mengen aufteilen und den Experimentator dann fragen, ob der Versuchsausgang in der ersten oder der zweiten Hälfte liegt. Da beide Hälften gleichwahrscheinlich sind, erfragen wir damit ein erstes Bit an Information. Die betroffene Hälfte unterteilen wir ebenso und erfragen ein weiteres Bit. So fahren wir fort, bis die letzte Frage uns genau einen der Ausgänge angibt. Wir haben dann
Die nächste, naheliegende Verallgemeinerung besteht darin, die obige Gleichung auch auf die Fälle anzuwenden, in denen N keine Zweierpotenz ist. Im allgemeinen erhält man dann kein ganzzahliges Vielfaches eines Bit als Informationsgehalt mehr. Das (nur) logarithmische Anwachsen ist in der folgenden Abbildung dargestellt.
Der so definierte Informationsgehalt z. B. einer Auswahl eines Zeichens aus einem Zeichensatz ist also ausschließlich durch die Statistik, also durch Wahrscheinlichkeiten, nicht aber durch die Semantik, d. h. die Bedeutung der Zeichen, bestimmt.

Wie der Informationsgehalt I(xi) ist damit also auch die Entropie ein subjektiv geprägter Begriff. Durchführungen des Versuchs können für den Experimentator die Wahrscheinlichkeiten ändern. Er lernt dann, den Ausgang besser vorherzusagen, und die Entropie nimmt, wie wir formal noch sehen werden, für ihn ab.
Bei N möglichen Versuchsausgängen ist die Entropie eine Funktion der N Wahrscheinlichkeiten pi. Wegen der Normierung verbleiben N−1 Freiheitsgrade.
Die Wahrscheinlichkeit, genau k Richtige zu haben, ist \[ p_k = \frac{\displaystyle{6\choose k}{{49-6}\choose{6-k}}}{{\displaystyle49\choose \displaystyle6}} \] Die Wahrscheinlichkeiten pk und ihre Beiträge zur Entropie sind in der folgenden Tabelle zahlenmäßig aufgeführt.
| k | pk | −pk ld(pk)
|
| 0 | 0.4359649 | 0.5223 |
| 1 | 0.4130194 | 0.5268 |
| 2 | 0.132378 | 0.3862 |
| 3 | 0.0176504 | 0.1025 |
| 4 | 9.68619 •10-4 | 0.0097 |
| 5 | 1.84498 •10-5 | 0.00029 |
| 6 | 7.15112 •10-8 | 0.0000017 |
 bei sieben gleichwahrscheinlichen Möglichkeiten.
Zwar liefern, wie definierende Gleichung zeigt,
sehr unwahrscheinliche Versuchsausgänge,
wenn sie auftreten, sehr viel Information.
Sie tragen aber vernachlässigbar wenig zum mittleren
Informationsgehalt, also zur Entropie bei.
Es ist daher völlig unkritisch, solche Ausgänge bei der entropiemäßigen
Bewertung eines Versuchs außer acht zu lassen.
bei sieben gleichwahrscheinlichen Möglichkeiten.
Zwar liefern, wie definierende Gleichung zeigt,
sehr unwahrscheinliche Versuchsausgänge,
wenn sie auftreten, sehr viel Information.
Sie tragen aber vernachlässigbar wenig zum mittleren
Informationsgehalt, also zur Entropie bei.
Es ist daher völlig unkritisch, solche Ausgänge bei der entropiemäßigen
Bewertung eines Versuchs außer acht zu lassen.
Bei einem Versuch mit zwei möglichen Ausgängen ist die Entropie wegen der Normierung der Wahrscheinlichkeit gleich \[\large H(X) = -p\text{ ld } p - \left(1-p\right)\text{ ld}\left(1-p\right) \equiv S(p), \] also eine Funktion von nur einer Variablen.
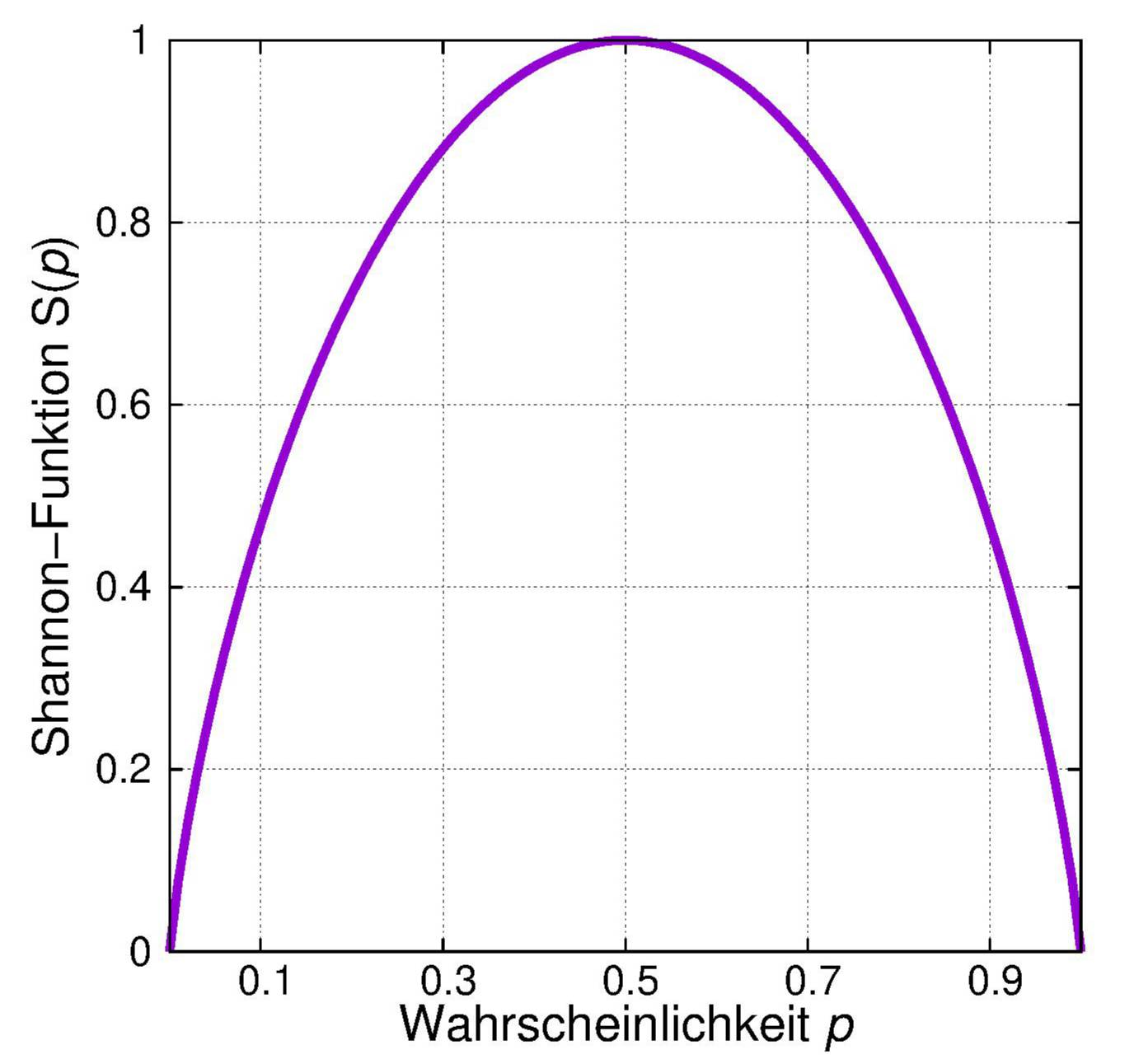
Die zweite dieser Gleichungen erhält man nach der Regel von de l'Hospital.

Dies gilt auch für Versuche mit mehr als zwei Ausgängen. Auch dann können wir den Satz aussprechen:
Die Entropie eines Versuches X mit den möglichen Ausgängen xi ist dann am größten, wenn alle Ausgänge gleichwahrscheinlich sind.

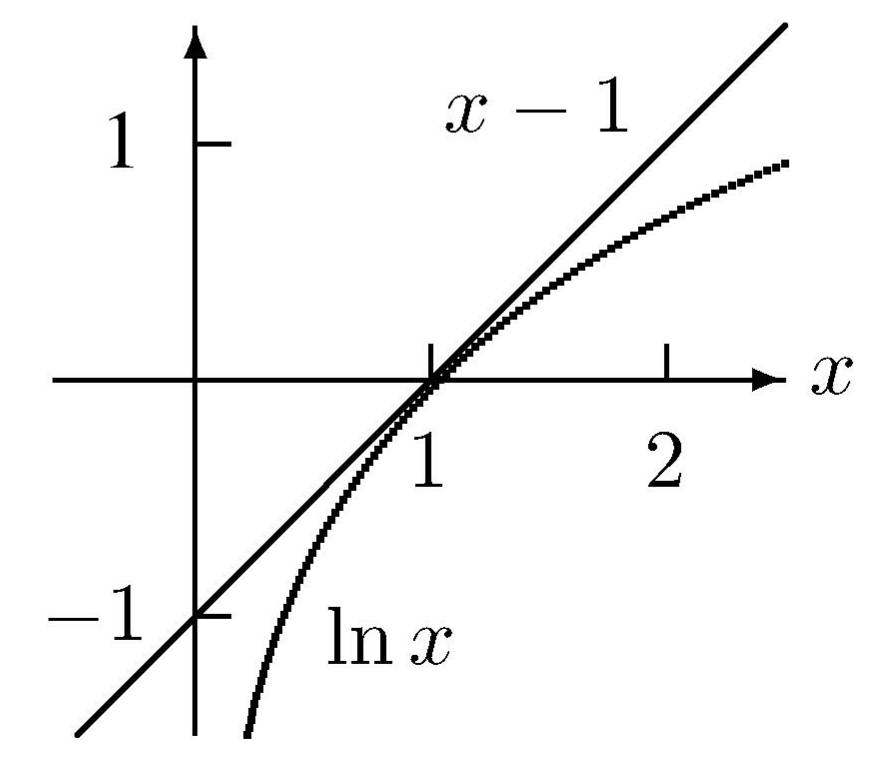
Das Gleichheitszeichen gilt offensichtlich, wenn x = 1 ist. Für alle anderen positiven x ist y(x) := ln x − x+1 negativ, denn die erste Ableitung y'(x)=(1-x)/x verschwindet nur für x = 1, und die zweite Ableitung y''(x) = −1/x^2 ist dort negativ, so daß y(x) dort sein einziges Maximum mit dem Wert Null hat


| ||
| = | 
| |
| ≤ | 
| |
| = | 
| |
Das Gleichheitszeichen gilt genau dann, wenn das Argument des Logarithmus gleich Eins ist, d. h. wenn

Nach dem Prinzip der maximalen Entropie (Jaynes, 1957) gilt die Umkehrung dieses Satzes, daß nämlich, wenn außer der Normierung keine weiteren Einschränkungen für die Wahrscheinlichkeiten bestehen, sie für maximale Entropie alle gleich groß sein müssen.
Auch bei mehr als zwei möglichen Versuchausgängen ist die Entropie dann Null, wenn einer von ihnen mit Sicherheit, also mit der Wahrscheinlichkeit Eins auftritt und die die anderen die Wahrscheinlichkeit Null haben.
Als Maß für die Unvorhersagbarkeit eines Versuches stellt die Entropie den Wert eines Versuchs dar. Je kleiner nämlich seine Entropie ist, um so sicherer kann man seinen Ausgang vorhersagen und um so eher kann man auf seine Durchführung verzichten.
Formal kann man die Entropie eines Versuchs durch die folgenden drei Eigenschaften definieren:



© Günter Green
zurück
weiter
zurück zum Anfang
17-Sep-2018